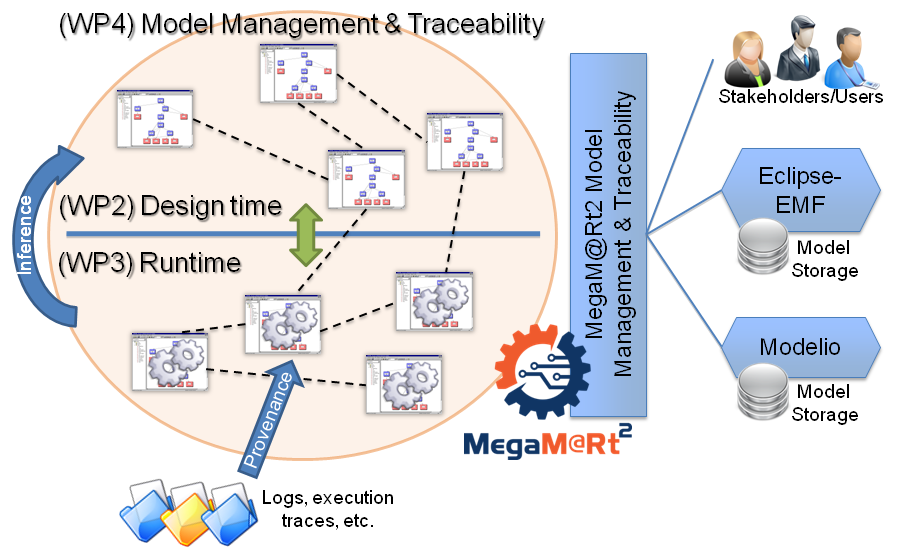
As part of our initial work on MegaM@Rt2, we have worked on an overall state-of-the-art of existing model management and traceability solutions. This document (deliverable D4.1. in the context of the project) presents the main principles and approaches related to scalable model storage, model querying, model handling and management of relationships and links among models and among models and other kinds of modeling artifacts, notably via model views and/or so-called megamodels. In the report we also focus on the available traceability and interoperability solutions. We describe both existing research approaches as well as some more business-oriented tools or environments, and we provide a list of relevant technical solutions provided by the project’s partners.
Indeed, MegaM@Rt2 heavily relies on the joint use of models of various and varied natures (e.g. design models defined manually by engineers, runtime models generated from system executions) as well as sizes (e.g. from relatively small design models to very large runtime ones). We intend to provide support for the continuous development and validation of complex systems via a feedback loop from runtime to design time. Our main goal in WP4 is thus to elaborate on the required glue between the artifacts produced in WP2 (e.g. design models) and the ones produced in WP3 (e.g. runtime models). As a result, we expect to provide a global MegaM@Rt Model Management and Traceability framework, a core part of our MegaM@Rt2 overall solution to be deployed on the project’s use cases.
Deliverable D4.1 prepares the work for specifying this framework and helps to identify some of the key problems for us to tackle in the future (stay tuned for more news during the coming year). Among others, below are some big challenges we will need to work on during the project:
- Scalable model storage and querying – Current approaches are generally static and monolithic: one single serialization backend has to be selected first and then used systematically for a given model over time. Improvements should be performed in order to support loading/saving/accessing the same model from/to multiple database backends (e.g. relational DB vs. graph DB). It should also be possible to allow partitioning a model according to its intended use.
- Well-synchronized and verified model views – Fully updating a view is not always possible, techniques should be proposed to support different view/model update strategies (eventually in both directions) according to the expected view usages. For performance reasons, such view computations and updates should be performed incrementally when necessary. Significant progress could also be made in terms of model view presentation (automation of concrete syntax generation) and of overall security (e.g. access-control policies to views and related models).
- Performant and decentralized global model management – Recent approaches for file management could be taken as an inspiration for efficiently building and handling model fragments in the context of large sets of heterogeneous models. This raises several challenges concerning the decentralized edition of models (e.g. design models to be updated remotely) or performance and security issues (e.g. limited access required to some data in runtime models) among several teams and/or locations.
- Efficient integration of inter-model traceability and interoperability support – Research and improvements still have to be performed regarding the automated production of the required trace links between different heterogeneous (e.g. in the case of model transformations notably). Existing megamodeling approaches also need to be adapted and/or extended to efficientlydeal with the specific traceability information between design time and runtime models. Finally, available links should be analyzed and exploited further to provide the expected feedback loop.
Check out our deliverable page to download the full D4.1 PDF file!

I am an engineer doing research and managing innovative projects on software engineering for the NaoMod team (formerly AtlanMod team) with particular focuses on 1) the design and application/adaptation of model-based techniques and architectures to real industrial problems (reverse engineering, tool/language interoperability and evolution, model management and traceability, Cloud Computing, etc.) and 2) the dissemination and/or industrialization of corresponding research results and prototypes (e.g. knowledge and technology transfer to companies).
Trackbacks/Pingbacks