Model views are fundamental when (many) different kinds of models are used for engineering complex (cyber-physical) systems. This is a challenge of primary importance in the MegaM@Rt2 context, cf. our already released Deliverable D4.1. For more details on existing approaches, check out our previous post on our survey of existing model view approaches. The main benefit of using model views is to collect in a transparent way information spread among different models. Without such views, engineers have to query the different models one by one and aggregate the results by themselves. Instead, using views, we can express queries traversing several contributing models. These queries are computed naturally as if dealing with single models.
MegaM@Rt2 – Runtime ↔ Design time Feedback
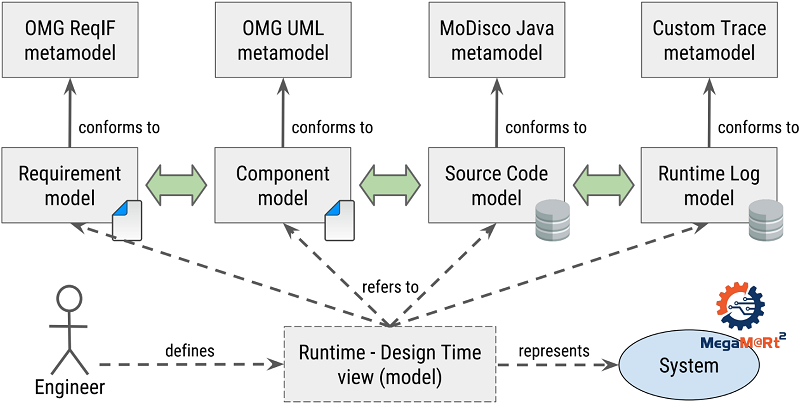
MegaM@Rt2 aims at incorporating methods and tools to develop a generic continuous system engineering and validation approach. One of its main expected contributions is a runtime ↔ design time feedback loop (re)usable in different industrial contexts. Let us realize it via a view gathering four models covering both runtime and design time system aspects. As shown on the figure below, this view relies on:
- A runtime log model (that conforms to a simple trace metamodel).
- A Java code model (that conforms to the Java metamodel from MoDisco).
- A component model (that conforms to OMG UML).
- A requirement model (that conforms to OMG ReqIF).
The runtime log model and (to a lesser extent) the Java model are runtime models. They are potentially very large, especially the runtime log model representing actual system execution traces. Thus, to store/access them in a scalable way, we want to rely on database model persistence frameworks. The component model and requirement model are design models. They are generally of a reasonable size compared to the runtime ones (they are very often manually specified). Hence, standard modeling frameworks handle them by relying on their in-memory constructs and/or files.
We can query such a view combining different models as any regular model, in order to extract relevant data. For example, we can obtain all the requirements relating to a given execution trace (runtime to design time traceability). Or, the other way around, we can get all the execution traces that correspond to a particular requirement (design time to runtime traceability). We can imagine many other queries also relevant in MegaM@Rt2, according to different needs of the industrial partners.
Our Integration Approach for Scalable Model Views
We provide an integration approach supporting such scalable views in this paper we published/presented at ACM/IEEE MODELS 2018. These model views are built on top of several models where some are too large to be loaded, handled and stored only in memory. We can do it by relying on models persisted and manipulated, when necessary, using appropriate database backends. We show in the figure below the general approach we followed.
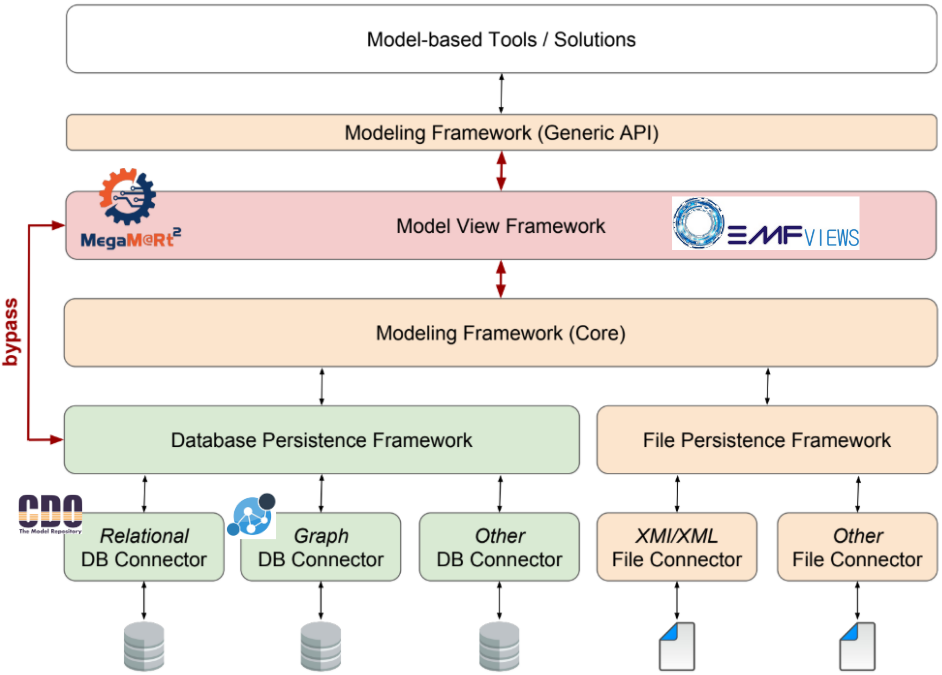
A Modeling Framework usually has two main parts. The first one is a Core component providing the inner behavior (i.e. model manipulation facilities). The second one is a Generic API as the interface provided externally for (re)use by Model-based Tools. The Modeling Framework also often provides a base File Persistence Framework relying on the local file system (file import/export capabilities in different formats). This default mechanism stores the design models from our example described earlier in this post. Database Persistence Frameworks connect the modeling framework to databases of various kinds (relational, graph, etc.). These solutions typically store larger models (e.g. the runtime models from our example) with a reduced memory footprint.
The Model View Framework correctly integrates with the Modeling Framework and complies with its Generic API. This allows client applications to query views as regular models. Moreover, for model views to scale with large models, the Model View Framework has to leverage the characteristics of the Database Persistence Frameworks. This notably requires various refinements and optimizations from both sides.
Realization and Challenges
To realize this integration approach in practice, we used our EMF Views framework as the solution for model views. In addition, we used the CDO and NeoEMF frameworks as database persistence solutions for models. We had to deal with four important challenges:
- Building Views on Heterogeneous Model Sources.
- Persisting the View Information in a Scalable Way.
- Optimizing the View Loading and Element Access.
- Optimizing the View Querying.
Check out the full paper for more details on these four challenges and on how they have been implemented and evaluated!

I am an engineer doing research and managing innovative projects on software engineering for the NaoMod team (formerly AtlanMod team) with particular focuses on 1) the design and application/adaptation of model-based techniques and architectures to real industrial problems (reverse engineering, tool/language interoperability and evolution, model management and traceability, Cloud Computing, etc.) and 2) the dissemination and/or industrialization of corresponding research results and prototypes (e.g. knowledge and technology transfer to companies).