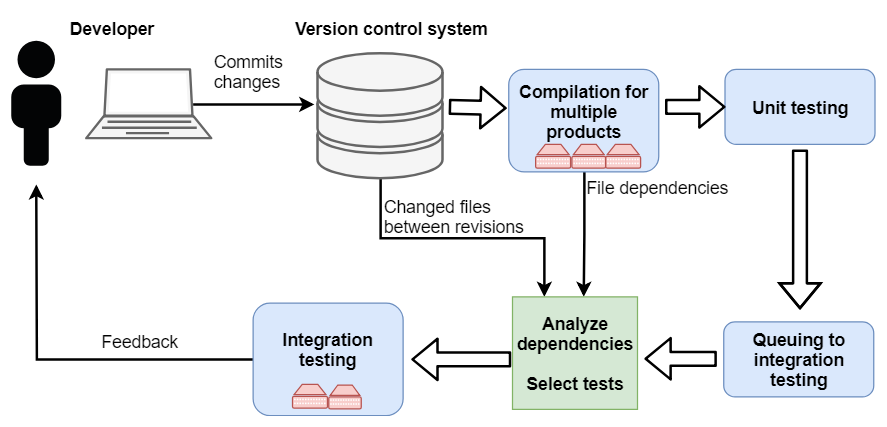
In Continuous Integration (CI) systems, new changes in code are integrated into the existing codebase continuously. In such systems, it is important that the developers committing the changes receive feedback of their latest changes quickly in order to know if the integration was successful. However, often the changes are committed frequently which creates a challenge for the integration testing. An entire set of available (regression) tests may take a long time to run and executing all of them is not feasible due to the limited time frame.
In our CI environment, the codebase in Version Control System (VCS) contains source code (C/C++) and auxiliary files of multiple hardware products (or variants), which means they share lots of common code. The integration testing is conducted on a limited number of hardware targets. Executing all available tests for all of the products takes a couple of hours to run. This can build up a queue for built changes to reach the integration testing phase.
An initial selective testing method was created to address the challenge of long-lasting integration testing. Finding dependencies between changes in the code and the products is the key to reducing the number of executed tests per committed change. The coverage of the tests was unknown, and therefore mapping changes directly to the test suites was not possible. After determining products that are dependent of recent changes, it was possible to only test the affected products.
The files in the VCS can be divided into three different categories: source code files, test code files, and metadata files. The source code changes were mapped to certain products by means of collecting dependency files created by compilers when the code was compiled. The test code files are known to test a certain module, and if that module is found in the dependency files of the product, it is dependent of the changed test code file. Certain metadata files were parsed separately to find relevant changes, for example, if any other related component of tested software was changed. All changed files between the two revisions were obtained from the VCS by inserting the revision of the previously tested build and the revision of a build about to be tested.
Thus, our proposed test selection method has the following procedure:
- Find all changed files between the current and previously tested revision.
- Analyze which products are dependent of changed files.
- Execute tests for builds of the dependent products only.
The method managed to reduce the number of executed tests, by skipping the testing of approximately 15% of the products. The resulted as speed up in the integration testing phase enables a shorter throughput time of committed changes, and a faster feedback cycle for the developers. The fault detection capability of the integration testing was not detected to decrease after utilizing this test selection method. However, for further benefits, this method is planned to be extended with a test coverage tool, which will enable selection of a small subset of the tests per product depending on the magnitude of the submitted changes. Overall this approach was the first step on a journey of making the testing more focused on the code changes, but it still needs future improvements to become more efficient.
You can read the full details of this work here: http://jultika.oulu.fi/Record/nbnfioulu-201806062460