A Two-Layer Component-Based Allocation for Embedded Systems with GPUs by Gabriel Campeanu and Mehrdad Saadatmand (Designs 2019, 3(1), 6; https://doi.org/10.3390/designs3010006) describe a way to cope with the increasing demands of modern embedded systems.
Component-based development is a software engineering paradigm that can facilitate the construction of embedded systems and tackle its complexities. Indeed, modern embedded systems have more and more demanding requirements. For instance, the Google autonomous car ( i.e., the Waymo project) handles 750 MB of data per second that is produced by its sensors (e.g., LIDAR). One way to cope with such a versatile and growing set of requirements is to employ heterogeneous processing power, i.e., CPU–GPU architectures. A GPU is a processing unit that is equipped with hundreds of computation threads, excelling in parallel data-processing.
The new CPU–GPU embedded boards deliver an increased performance but also introduce additional complexity and challenges. In particular, the software-to-hardware allocation is already not an easy task: when having several processing units of different kinds and with different capabilities, a major design challenge will then be in finding an optimal allocation of software artifacts (e.g., components) onto the processing units in a way that system constraints are also met and not violated. With the GPU in the landscape, the allocation becomes even more complicated and challenging. The software is characterized now, besides the properties regarding the CPU resources, with properties that refer to GPU such as the GPU memory usage or the execution performance on the GPU.
In this work, we use the component-based development (CBD) to construct embedded systems with GPUs. In particular, we address the component-to-hardware allocation for CPU–GPU embedded systems. The allocation for such systems is much complex due to the increased amount of GPU-related information. For example, while in traditional embedded systems the allocation mechanism may consider only the CPU memory usage of components to find an appropriate allocation scheme, in heterogeneous systems, the GPU memory usage needs also to be taken into account in the allocation process.
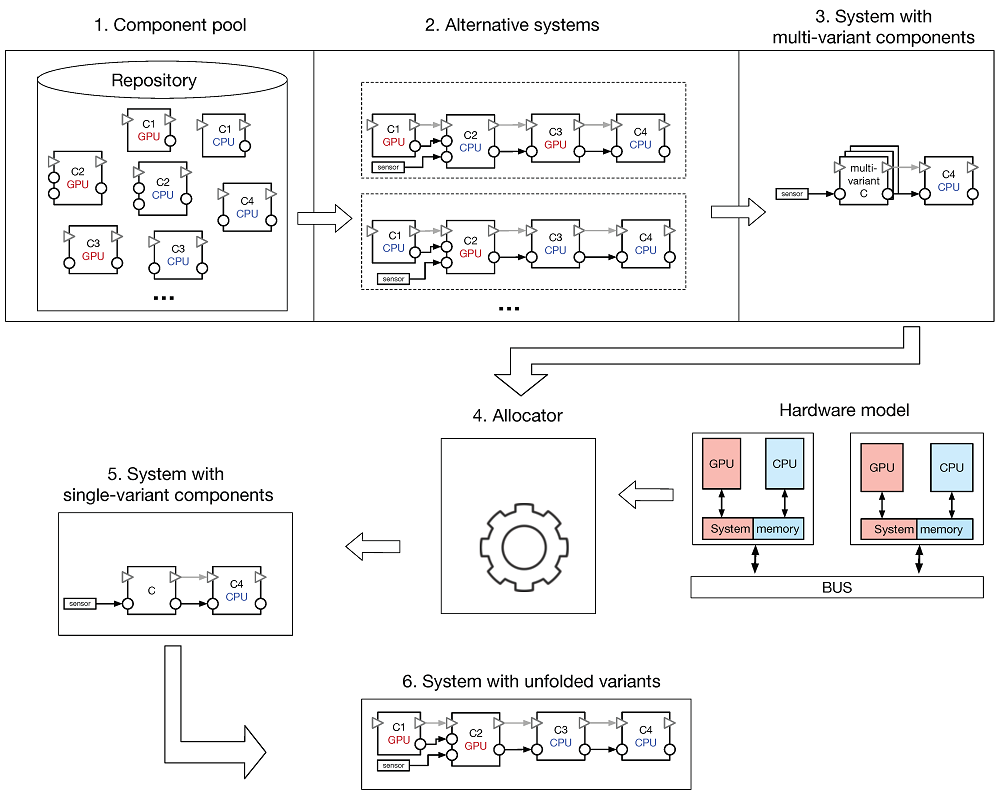
This paper aims at decreasing the component-to-hardware allocation complexity by introducing a two-layer component-based architecture for heterogeneous embedded systems. The detailed CPU–GPU information of the system is abstracted at a high-layer by compacting connected components into single units that behave as regular components. The allocator, based on the compacted information received from the high-level layer, computes, with a decreased complexity, feasible allocation schemes.
More specifically, both layers describe a same system that has GPU computation; the difference resides in the level of information that characterizes each layer. The first layer, seen as regular description of the architecture, encloses all information (e.g., component communication links) of all alternatives. The second layer compacts different alternatives with the same functionality into single components with multiple variants. Each of the variants of the resulted components, is characterized by a set of properties that reflect the requirements of all components contained by its corresponding alternative.
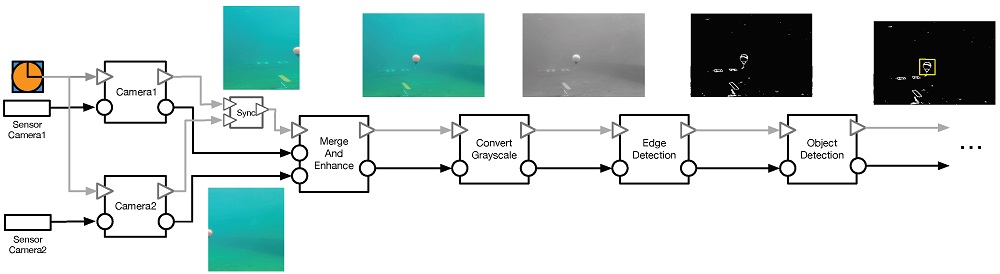
In the last part of the paper, the two-layer allocation method is evaluated using an existing embedded system demonstrator; namely, an underwater robot depicted in the featured image that illustrates this post.
ICREA Research Professor at Internet Interdisciplinary Institute (UOC). Leader of the SOM Research Lab focusing on the broad area of systems and software engineering. Visit jordicabot.com